





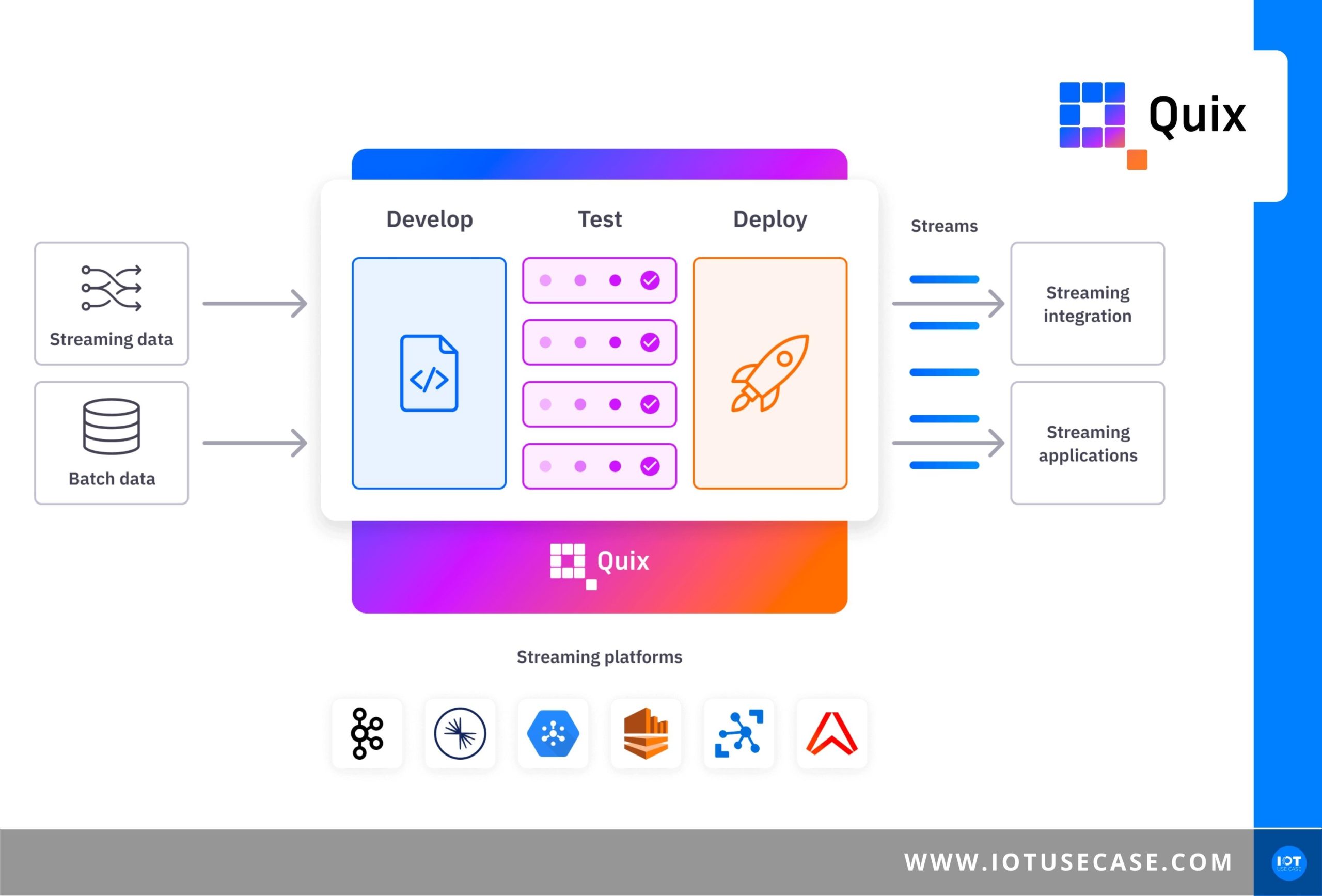
Die Nutzung von Event-Streaming boomt, aber die Arbeit mit Live-Daten ist oft schwierig. Das Ziel unseres heutigen Podcastgastes Quix ist es, Data-Scientists und Maschinenbauingenieuren zu helfen, Live-Daten schneller in ihren Anwendungen zu nutzen. Auf der PaaS (Platform-as-a-Service) kann der gesamte Workflow gemanaged werden – und das auf Basis von Python!
Folge 77 auf einen Blick (und Klick):
- [10:55] Herausforderungen, Potenziale und Status quo – So sieht der Use Case in der Praxis aus
- [23:48] Lösungen, Angebote und Services – Ein Blick auf die eingesetzten Technologien
- [35:18] Ergebnisse, Geschäftsmodelle und Best Practices – So wird der Erfolg gemessen
Zusammenfassung der Podcastfolge
Was ist Event-Streaming und wie können Unternehmen davon profitieren? Wie hilft es Entwicklern wie Data Engineers der IT Operations oder Mechanical Engineers? Welche Rolle spielt Kafka*? Und was hat Kubernetes, das von Google entwickelte Open-Source-System zur Verwaltung von Container–Anwendungen, damit zu tun?
Zu Gast in dieser Folge des IoT Use Case Podcast ist Clara Hennecke (Streaming Advocate, Quix), die genau diese Fragen beantwortet. Quix hilft Kunden aus unterschiedlichsten Industriebranchen mit einem Tool, das Entwicklern die Möglichkeit gibt, auch ohne IoT-Vorkenntnisse Echtzeit-Daten aus unterschiedlichster Infrastruktur zu laden, Daten zu transformieren und dabei, Daten in unterschiedlichsten Systemen bereitzustellen. Die Quix-Lösung setzt auf Python und bietet nicht nur die Technologie selbst an, sondern lässt gesamte Workflows von selbst managen.
In drei Use Cases tauchen wir in dieser Folge genauer ein:
1. Intelligentes Stethoskop von eMan aus dem Bereich der Medizin
2. Mobility IoT im Rennsport
3. Komponentengeschäft eines britischen Unternehmens für CNC-Fräsmaschinen.
Podcast Interview
Hallo Clara, du bist sogenannter Streaming Advocate bei Quix. Ihr seid in einem bestimmten Marktsegment unterwegs; aber lass uns zunächst bei dir bleiben: Was ist ein Streaming Advocate und welchen Hintergrund hast du?
Clara
Mein Titel klingt für viele möglicherweise nichtssagend. Im Grund besteht meine Rolle darin, sehr viel über Streaming Processing zu sprechen. Das ist einerseits mit unseren Kunden, potenziellen Kunden, aber auch Industrieexperten, um das Feedback intern an unser Team weiterzugeben, und andererseits, um Aufklärungsarbeit zu leisten. Bei Stream Processing – darüber müssen wir uns bewusst sein – sprechen wir über eine Technologie, die sehr innovativ ist. Häufig ist nicht die Frage, was konkret die beste Technologie ist. Sondern zunächst, worum handelt es sich und wie kann es meinem Business helfen?
Wie ich es verstanden habe, seid ihr mit Quix vom Kerngeschäft her grob gesagt bei der Softwareentwicklung tätig – Platform as a Service. Ihr bringt bei euch eine Lösung für IoT-Applikationen mit, wo ich zu einer Plattform einen Zugang bekomme und mit meinen Echtzeit-Daten arbeiten kann, mit unterschiedlichen Bausteinen, die dort bereits vorhanden sind. Sowohl für die Anbindung von Daten, als auch die Transformation von Daten und die Bestimmung des Ziels, wo beispielsweise die Daten hinlaufen sollen. Seien es Dashboards oder andere Dinge. Wir bieten auch die Möglichkeit, für Machine Learning ein Tool zusammenzufassen.
Es gibt viele Plattformen am Markt mit unterschiedlichen Lösungen. Wie funktioniert eure Lösung genau und was ist der Unterschied zu anderen?
Clara
Du hast das ganz gut zusammengefasst. Worum handelt es sich bei Streaming? Es gibt in einem Unternehmen viele Anwendungen. Eigentlich werden Daten immer in Echtzeit erzeugt; sei es eine Temperatur, die gemessen wird, oder eine eingehende Bestellung. Und wenn wir diese Echtzeit-Daten nehmen und innerhalb unserer IT-Infrastruktur an verschiedene Anwendungen weiterleiten, dann nennen wir dieses Datensenden-von-A-nach-B »Streaming«. Um diese Daten zu versenden, verwendet man verschiedene Streaming-Technologien, wie zum Beispiel Kafka.
Wenn man die Daten nicht einfach nur von einem Punkt zum anderen versenden möchte, sondern sie in Echtzeit transformieren möchte, dann handelt es sich um Stream Processing. Da gibt es am Markt verschiedene Technologien. Confluent bietet dazu KSQL oder Kafka Streams an. Quix ist ebenfalls eine Stream-Processing-Lösung. Was uns unterscheidet, ist, dass wir unseren Schwerpunkt auf das Entwickeln mit Python setzen und andererseits nicht nur eine Technologie anbieten, sondern eine gesamte Plattform, in der ein kompletter Workflow gemanagt werden kann.
Wer mehr über Echtzeit-Daten, Definitionen und, was Confluent genau macht, erfahren möchte, wird in den Shownotes mehr dazu finden.
Confluent ist euer Partner, ihr setzt solche Lösungen, die es bereits gibt auch bei euch um, arbeitet dann aber verstärkt auf eurer Lösung mit Python, oder?
Clara
Genau, unsere Technologie ist komplementär zu Kafka. Das heißt, viele unserer Kunden implementieren zuerst Kafka, und bilden damit die Rohre der Echtzeitdaten in ihrem Unternehmen und setzen dann unsere Plattform auf diese Rohre auf, um die Entwicklungsumgebung mit Python zu haben und damit entwickeln zu können.
Am Ende handelt es sich bei Python um eine Programmiersprache, die ebenfalls in IoT-Lösungen zum Einsatz kommt, auf die ihr setzt.
Clara
Richtig, wenn wir in den Datenbereich generell schauen, gibt es dort zwei Sprachen, die dominieren. Zum einen SQL und Python, wobei SQL eher für analytische Abfragen verwendet wird. Eher für Fragestellungen wie: „Wie viele Teile habe ich in den letzten drei Monaten gefertigt?“ Viel wird dort auf Badge-Daten, also auf persistenten Daten gearbeitet. Wobei Python die Sprache für Data Science und Machine Learning ist, sprich komplexere Anwendungen, wie Vorhersagen oder Anomalieerkennungen.
Um eine Benchmark zu schaffen: Etwa 60 bis 70 Prozent aller Machine-Learning-Data-Science-Projekte werden mit Python durchgeführt. Dadurch haben wir ein großes Ökosystem um die Sprache herum angesiedelt.
Es ist spannend in diese Datenbanken-Welt einzutauchen. Es ist eine Plattform, die Entwicklern dabei hilft, mit Live-Daten schneller ihre Anwendungen zu nutzen oder nutzbar zu machen. Der Markt an IT-Fachkräften ist eine Herausforderung aktuell. Das wird vor allem eure Zielgruppe sein mit der ihr sprecht oder sind das von euren Kunden die Entwickler in den Unternehmen?
Clara
Das ist so in Ordnung. Um auf den Punkt unserer speziellen Lösungen für IoT, auf welche Lösungen wir uns spezialisieren und wie wir dort ausgerichtet sind, zurückzukommen: Die Plattform generell ist zunächst industrieunabhängig. Denn in verschiedensten Branchen besteht ein Bedarf und auch ein Nutzen durch Stream Processing. Das geht über E-Commerce, die Finanzbranche, die Telekommunikationsbranche oder Logistikbranchen, aber natürlich spielt IoT eine sehr große Rolle.
Wir haben Kunden sowohl im IIoT-Bereich, aber auch in Bereichen wie Micromobility oder Logistik. Wenn wir dann über die Personen in den Unternehmen sprechen, die unsere Plattform nutzen, dann handelt es sich im weitesten Sinne um Entwickler, die mit Python entwickeln. Das sage ich so weit ausgedehnt, weil es je nach Unternehmen sehr unterschiedliche Leute sein können. Häufig sind das Personen in einem Data Team; Data Scientists oder Data Engineers. Aber wir sehen auch besonders im IIoT-Bereich, dass es oft Maschinenbauingenieure sind, die dort die Anwendungsfälle, aber auch Fähigkeiten haben, diese Anwendungen mit unserer Plattform zu bauen.
Theoretisch gibt es viele dort draußen, die einen anderen Background haben oder aus der Automatisierungswelt kommen, aus der Programmierwelt, und diese können da erlernen, mit eurer Plattform in Richtung IoT-Entwicklung zu gehen.
Clara
Genau, das ist ein Ziel unserer Plattform. Dass wir sehr viel Komplexität wegabstrahieren und Entwickler dort keine Experten in der IT-Infrastruktur sein müssen. Sondern eher Experten darin, einen bestimmten Anwendungsfall abzubilden, im Code zu übersetzen und diesen Code zu schreiben und zu implementieren.
Warum ist das, was ihr tut, so wichtig? Was ist eure Vision am Markt? Vielleicht kannst du auch etwas zur Gründungsgeschichte erzählen.
Clara
Unsere vier Gründer kommen aus der Formel 1, im Rennsportbereich, wo sehr viele Daten gesammelt werden. Mir war es am Anfang nicht bewusst, dass es so ein großes Thema ist, jedoch ist ein solcher Rennwagen mit sehr vielen Sensoren ausgestattet, der auch viele Daten sendet, die dann in die Garagen weitergeleitet werden an die Teams, damit diese dort die besten Entscheidungen treffen können. Unsere Gründungsväter haben an diesen Lösungen gearbeitet, die diese Echtzeit-Datenstreams betreffen. Da kommt es darauf an, dass es sich wirklich um Echtzeit-Lösungen handelt.
Wir haben hier gemerkt, dass das Ganze sehr komplex ist und es zu dem Zeitpunkt keine Möglichkeit am Markt gab, sich einfach auf den Code und auf die Dinge, die einen Wert schaffen, zu fokussieren. Ein neues Modell entwickeln, ein neues Modell testen, ein neues Modell deployen gehören ebenfalls dazu. Die ganzen Interaktionen von den Software Engineers zu anderen Entwicklern sind sehr langwierig und man musste dort sehr viele Schleifen fahren. Es dauert sehr lange, bis ein neues Modell vom Schreiben des Modells auch wirklich in die Produktion geht. Das Ganze möchten wir vereinfachen und demokratisieren.
Man muss zugeben, dass Streaming technisch gesehen sehr komplex ist. Was im Hintergrund bei einem Kafka passieren muss, damit kein einziges Event verloren geht, ist sehr anspruchsvoll. Es ist eine sehr machtvolle Technologie. Wenn wir konkret über unsere robuste Plattformbasis Kafka sprechen, möchten wir einem weiteren Personenkreis ermöglichen, mit dieser Technologie zu arbeiten und wertstiftende Anwendungen zu bauen.
Herausforderungen, Potenziale und Status quo – So sieht der Use Case in der Praxis aus [10:55]
Weil die Themen buzzwordlastig sind, benutze ich gerne Beispiele aus der Praxis. Welche Use Cases bearbeitet ihr aktuell und was sind die Lösungen?
Clara
Wir haben Use Cases in verschiedensten Branchen. Viel kommt aus der Finanz- und E-Commerce-Branche. Aber wenn wir uns auf den IoT-Bereich fokussieren, dann habe ich drei Use Cases mitgebracht, auf die ich heute eingehen werde. Der erste Use Case kommt aus dem medizinischen IoT-Bereich. Dabei handelt es sich um ein Start-Up aus England, eMan. Die Mission von eMan ist es, ein intelligentes Stethoskop zu entwickeln, welches aufgenommene Töne in Echtzeit auswertet und Informationen über Zustand der Lunge, des Herzens, des Darms, des Blutflusses zieht. Dabei werden Audiodateien dieses Stethoskopes genommen, über Bluetooth an ein Smartphone gesendet, welches dann die Daten in die Quix Cloud sendet. Dort werden die Daten verarbeitet, Visualisierungen transformiert und dann zurück an das Smartphone gesendet, sodass ich direkt auf meinem Smartphone Informationen über den Zustand erhalten kann. Das ist ein spannender Anwendungsfall, welcher einen sehr großen Fortschritt im Medizinbereich bringen kann.
Das ist der Hauptbereich bei uns, wo wir viele Produktentwickler bei uns im Netzwerk haben, die sich damit beschäftigen, ihre Geräte und Komponenten smart zu machen und ein Angebot zu schaffen. Sie setzen ebenfalls auf euch.
Welche Use Cases hast du noch?
Clara
Bei dem zweiten Use Case springen wir wieder in den Rennsport hinein, in den Mobility-IoT-Bereich. Während eines Rennens werden riesige Mengen an Daten von verschiedensten Sensoren gesammelt. Bei dem Kunden hier handelt es sich um eine Firma, die sich auf die Konnektivität der Rennwagen spezialisiert hat. Diese Daten müssen von den Autos versendet werden; die Problemstellung ist aber, dass ein Wagen sich während eines Rennens schnell bewegt und es viele Einflüsse gibt, die Auswirkungen auf die Netzwerkqualität haben, wie beispielsweise die Zuschauer oder auch das Wetter. Da gibt es während eines Rennens unterschiedliche Möglichkeiten, welches Netzwerk aktuell das beste ist. Der Kunde hat dann die Quix-Plattform verwendet, um Machine-Learning-Modelle zu entwickeln, die in Echtzeit die Qualität der Netzwerkverbindung auswerten und zu jedem Zeitpunkt die Verbindung zu dem Netzwerk herstellen, welches die beste Verbindung hat. Das Ganze kann sich bis zu 15-mal pro Sekunde ändern. Dort haben wir einen hohen Effizienzgewinn und eine großer Steigerung der Konnektivität erzielen können.
15-mal pro Sekunde ist wirklich viel. Für die, die über den Use Cases mehr wissen möchten und im Nachgang Kontakt zu euch haben möchten, verlinke ich alles Notwendige in den Shownotes.
Welchen Use Case schauen wir uns heute im Detail an?
Clara
Der spezielle dritte Use Case kommt aus dem IIoT-Bereich. Den Namen des Kunden können wir leider nicht nennen, dennoch versuche ich genug Kontext zu geben, um sich das bestmögliche Bild machen zu können. Es handelt sich um ein britisches Unternehmen, welches Komponenten für den Luftfahrt-, Automobil-, Verteidigungs- und Energiesektor herstellt. Größtenteils haben sie CNC-Maschinen im Einsatz und sich auf Autonomous Manufacturing spezialisiert. Das Ziel beim autonomen Manufacturing ist, ein Netzwerk aus den Maschinen und Robotern herzustellen, aber auch eine weitere Planungs- und Steuerungssoftware in dem Unternehmen zu bilden. Wichtig ist es, das alles so zu verbinden, dass es miteinander kommuniziert und sich automatisch aufeinander einstellt, um am Ende eine hochgradig agile und automatisierte Produktion zu ermöglichen.
Es geht nicht nur um die Vernetzung von Maschinen und Anlagen, sondern auch um die Integration von unterschiedlichen Systemen, die der Kunde dort bereits hat.
Es geht um einen Kunden, der einige CNC-Fräsmaschinen und Roboter verschiedenster Linien hat. Wie sehen die Prozesse hier aus?
Clara
Damit es einfacher wird, nochmal kurz zu dem Use Case: Wenn man über Autonomous Manufacturing spricht, gibt es viele Prozesse, die wir uns dort anschauen können. Einer der ersten konkreten Prozesse, auf die sich der Kunde fokussiert hat im Datenverarbeitungsbereich, ist die Fabrikationsplanung. Bei der Fabrikationsplanung gibt es Planungssoftware, die das bereits unterstützt – wie genau meine Prozesse ablaufen, wann welches Teil auf welchen Linien gefertigt wird. Dem Kunden hat das aber nicht ausgereicht; insbesondere dadurch, dass Fabriken sehr heterogen und individuell sind. Jede Fabrik hat andere Prozesse, andere Maschinen und andere Software im Einsatz. Fabrikationsplanung umfasst im Optimalfall alle Komponenten.
Es ist schwierig bis unmöglich, standardisierte Software einzukaufen, die das Zusammenspiel meiner persönlichen einzelnen Komponenten kennt und optimal aussteuert. Deshalb ist es das Ziel vom Kunden, eine Situation zu schaffen, in der am Ende eine CAD-Datei von seinem Kunden reinkommt, diese automatisch berechnet, wie die Maschine konfiguriert sein muss, die die geschätzte Bearbeitungszeit kalkuliert, das Teil automatisch in die Planung aufnimmt, und man dadurch die Lieferzeit und Produktionsauslastung verbessert und Effizienz in der gesamten Produktion und Supply Chain steigert.
Es gibt Herausforderungen, vor denen eure Kunden stehen, weshalb sie auch auf euch zukommen. Was sind diese Herausforderungen, die ihr im Alltag seht?
Clara
Das sind zwei Dinge. Viele denken, dass sich das Ganze widersprechen kann, aber es ist, was unsere Plattform im Endeffekt vereint: Einerseits eine sehr resiliente und anspruchsvolle IT-Infrastruktur. Ein Stream-Processing-System dauert schnell sechs bis zwölf Monate und bringt hohe Kosten mit sich. Beim Kunden sprechen wir über »High-Frequency-Daten« und bewegen uns im 100-kHz-Bereich. Das heißt, dass bestimmte Anwendungen 100 000 Datenpunkte pro Sekunde sammeln. Da kommen – als Benchmark – schnell 5 GB Daten in der Minute zusammen. Das sind sehr hohe Anforderungen an eine IT-Infrastruktur.
Andererseits ist es der Wunsch, selbst Kontrolle über die Daten zu haben und die Expertise selbst intern aufzubauen. Da insbesondere unser Kunde das als Kernkompetenz gesehen hat, gehen dort Autonomous Manufacturing und Machine Learning einfach Hand in Hand. Außerdem wurde der Vorteil darin gesehen, dass die Inhouse-Ingenieure die Maschinen und Prozesse sehr gut kennen und daher ihre Anforderungen genau an die Modelle weitergeben und abbilden können.
Das beides zu vereinen war die Herausforderung, die unser Kunde hatte und weshalb wir uns für eine Zusammenarbeit zusammengefunden haben.
Beim Rennwagen haben wir Wetter- oder Lokalisierungsdaten; bei dem Medizin-Thema sind es möglicherweise Audiodaten. In dem konkreten Fall geht es um verschiedenste Daten, also beispielsweise Fabrikationsplanungsdaten und CNC-Fräsdaten. Was sind Daten, die für euren Kunden wichtig waren und verarbeitet werden mussten?
Clara
Wenn man sich das übergeordnet anschaut, lassen sich die Daten in zwei Arten aufteilen. Einmal sind es die Echtzeitdaten in Form von Events. Die andere Art sind Kontextdaten. Bei den Echtzeitdaten handelt es sich um Zeitreihendaten (Time Series Data), die mit einem bestimmten Zeitstempel versehen sind. Im speziellen Fall des Kunden waren es insbesondere die Daten der Sensoren und Maschinen. Beispielsweise eine bestimmte Operation startet gerade oder sie stoppt, die genaue Position des Schneidkopfes oder dass ein Teil gerade die Maschine verlassen hat. Einmal, was auf meinem Shopfloor passiert. Aber nicht nur dort gibt es Events und Echtzeitdaten. Sondern auch in meiner drumherum liegenden Planung von Steuerungssoftware. Eine neue Bestellung kommt rein oder eine Sendung wurde geliefert. Ich sehe in meinem ERP, dass sich Daten innerhalb meines Warenlagers bewegt haben.
Man hat einmal Echtzeitdaten. Aber das Ganze bringt oft relativ wenig ohne Kontextdaten. Man stelle sich vor, ich habe das Event, dass die Artikelnummer ABC auf der Maschine bearbeitet wird – aber das bringt mir wenig ohne den Kontext, zu wissen, was genau ABC ist. Ein wichtiger Kontext hierbei wäre, wie lange die Artikelnummer in der Vergangenheit durchschnittlich auf der Maschine benötigt hat. Dabei handelt es sich nicht um Echtzeitdaten, sondern um beständige Daten, die irgendwo in meinen Datenbanken liegen.
Wenn ich das richtig verstanden habe sind das Daten, die Kunden schon heute in ihren lokalen Systemen verfügbar haben, die dort abgerufen werden.
Clara
Richtig, dort werden dann Verbindungen zu den lokalen Systemen, zu den Datenbanken mittels Konnektoren und Schnittstellen erstellt und dann in das System eingespeist.
Was sind Anforderungen von euren Kunden, die mit euch an den Lösungen arbeiten? Sie wollen Kontrolle über die Daten behalten, dennoch setzt man auf einen externen Partner, der dann als Platform as a Service in mein Geschäftsmodell integriert ist.
Clara
Das Wichtigste ist zunächst, dass unsere Plattform flexibel ist. Der Kunde ist nie ein unbeschriebenes Blatt. Es gibt bereits Systeme, die wahrscheinlich zu einer Zeit implementiert wurden, in der noch nicht an Stream Processing gedacht wurde. Es gibt ein bestehendes Ökosystem, und dort ist es wichtig, dass wir uns sehr flexibel mit verschiedensten Datenquellen einfügen können. Auch sehr wichtig ist, dass die Unternehmen immer mehr Cloud-unabhängig sein wollen. Das heißt, dass sie sich nicht an einen bestimmten Anbieter binden möchten und beispielsweise nur mit Amazon Web Services für immer arbeiten wollen; sondern immer die Möglichkeit, das zu ändern. Das sehen wir ebenfalls als wichtige Anforderung, die immer mehr aufkommt.
Wenn ich mir vorstelle, dass euer produzierender Betrieb mit verschiedenen Lieferanten und Kunden arbeitet … jeder setzt auf eine andere Plattform. Da kann es sein, dass neue Anforderungen in diese Richtung reinkommen und dass man flexibler sein muss, oder?
Clara
Auf jeden Fall! Und dort wirklich die Schnittstellen zu den Systemen zu besitzen. Das ist eine der Prioritäten, auf die wir uns fokussieren, dort ein breites Ökosystem zu erstellen.
Gibt es noch weitere Anforderungen?
Clara
Das ist die grundlegende Anforderung der Kunden an uns. Daneben gibt es noch Dinge, wie zum Beispiel Datensicherheit, die einfache Bedienbarkeit der Plattform, die Resilienz, die Skalierbarkeit der Plattform oder auch die Kosten, weil man sich nicht auf eine Plattform festlegen will in den nächsten fünf Jahren – diese wächst dann und erzeugt viel mehr Daten –, aber dann mit sehr hohen Kosten rechnen muss. Das sieht man leider bei anderer Software immer mehr, dass da die Kunden mit relativ kleinen Daten anfangen, wie zum Beispiel einem ersten PoC, dann das Ganze ausweitet – was sehr schön und auch das Ziel ist –, aber dann mit hohen Kosten konfrontiert ist. Das ist jedoch bei uns nicht der Fall.
Lösungen, Angebote und Services – Ein Blick auf die eingesetzten Technologien [23:48]
Ich selbst durfte bereits bei euch reinschauen und habe einen Zugang erhalten, wie das bei euch funktioniert. Man bekommt zu eurer Plattform einen Login, wo es unterschiedlichste Bereiche gibt, die als Bausteine bereits fertig sind. Seien es Konnektoren für verschiedene Datenquellen, die unter anderem aus Zeitreihendaten stammen können, aber auch verschiedenste Bestandsdaten, die man dort anbinden kann. Dann folgt bereits die Transformation der Daten und zum Schluss, wo die Daten landen sollen.
Ich finde das sehr gut umgesetzt, auch was du gerade mit der UX (User Experience) mit der Bedienbarkeit erwähnt hast. Wie funktioniert die Plattform nun aber genau? Ich möchte gerne mehr über die Datenaufnahme, deren Verarbeitung und weitere Schritte erfahren.
Clara
Die Datenaufnahme beginnt bei dem Laden der Daten in die Plattform. Da haben wir verschiedene Integrationen zu bestehenden Lösungen, sodass man einfach nur beispielsweise einen Token eingeben muss, und dort automatisch zu einer existierenden Datenbank verbunden wird, die man irgendwo hat; dort werden die Daten automatisch reingestreamt. Wir haben auch andere Schnittstellen wie eine »Web-Socket-Schnittstelle«, wo ein anderes System die Daten in unsere Plattform reinschreiben würde. Wir bieten auch eine klassische REST API, was wieder eine Schnittstelle wäre, wie wir die Daten in unser System hereinbekommen.
Ein Teil unserer Lösungen nennt sich »Quix Client Library«, was im Endeffekt ein Code ist, ein SDK (Software Development Kit), welches der Kunde in seine Software implementieren kann, und dort mit dem Code Snippet die Daten in unsere Plattform reinstreamt.
Da arbeiten verschiedenste Entwickler an der Lösung mit. Ihr habt bereits ein großes Ökosystem an unterschiedlichsten verfügbaren Schnittstellen aufgebaut.
Clara
Darüber hinaus arbeiten wir sehr aktiv daran, eine Community aufzubauen und sehen diese auch stark wachsen, die dann selbst neue Konnektoren schreiben, sodass sich das durch die Community weiterentwickelt und dort das Ökosystem weiterwächst.
Stichpunkt Open Source an der Stelle, damit man an dem Punkt die Möglichkeit hat, eigene Lösungen mit einzubringen. Hast du ein paar Beispiele von den Datenaufnahmen, welche Konnektoren das sind? Angenommen, ich habe Zeitreihendaten aus der CNC-Fräsmaschine – gibt es dann dort einen Konnektor dafür oder entwickelt sich euer Kunde den selber?
Clara
Das hängt davon ab, was genau auf dem Shopfloor verwendet wird, um diese Sensoren zu streamen. Beispielsweise war es beim aktuellen Use Case so, dass wir die Daten von den Sensoren an eine Linux-Box, die auf dem Shopfloor positioniert war, gesendet haben und die Daten im OPC UA Format – das ist ein gängiges Datenformat, das für die Verbindung von Maschinen genutzt wird – ankamen. In dieser Linux Box ist dann unsere Quix Client Library installiert, die diese Daten aus dem Format nimmt und dann in das Format transformiert, welches für Streaming und Zeitreihendaten optimiert ist, dann mit dem Internet verbunden ist und an die Cloud sendet.
Das ist ein neuerer Standard. Wenn ich eine alte Maschine habe, hätte ich aber auch die Möglichkeit, diese mit einer anderen Schnittstelle anzubinden, oder?
Clara
Das wäre auch möglich. Unsere Plattform ist da sehr flexibel. Wir haben noch nicht jeden Anwendungsfall out of the Box abgedeckt. Wir arbeiten dann aber in diesen Fällen oft mit dem Kunden so zusammen, dass wir einen Solutions Engineer bereitstellen. Der nimmt für den Kunden diese Anwendung vor und führt den initialen Aufwand durch. Es handelt sich meist um zwei bis drei Tage, in denen man diesen Code schreibt, der dann die Daten in ein Format verwandelt, dass sich in die Quix Plattform streamen lässt.
Wie funktioniert die Verarbeitung der Daten innerhalb eurer Plattform genau?
Clara
Es gibt diese drei Bereiche, dass Daten in der Plattform laden, dort transformiert werden und dann aus der Plattform weitergesendet werden. Wir sprechen jetzt über den zweiten Schritt, das transformieren der Daten, wo definitiv der Schwerpunkt unserer Plattform liegt und meiner Meinung nach auch der Schwerpunkt jeder Datenapplikation liegen sollte. Ich möchte wenig Zeit damit verbrauchen, Daten einfach nur irgendwo hinzuladen, sondern lieber dafür, die Transformation abzuschließen und den Wert zu schaffen. Das passiert auf unserer Plattform und lässt sich grundsätzlich in zwei Prozesse aufteilen. Einmal in Stream Processing, aber auch Badge Processing.
Zu Badge Processing: Das sind Datentransformationen, die nicht permanent, sondern zu einem bestimmten Zeitpunkt durchlaufen, wo ich keine Echtzeitanforderung habe. Dazu werden Daten in Datenbanken abgespeichert; das kann in unserer Plattform direkt passieren. Man kann mit einem Mausklick einstellen, dass man seine Daten persistieren möchte und in einer von uns verwalteten Datenbank abspeichern möchte, um die Daten beispielsweise zum Trainieren von Modellen zu verwenden. Andererseits haben wir auch Konnektoren zu Datenbanken wie Snowflake, Redshift oder Microsoft SQL Server, an die die Daten gesendet werden, wo ich meine Badge-Prozesse ablaufen lassen kann.
Das ist nicht unser Fokus. Wir sehen, dass dort Anwendungsfälle bestehen und ermöglichen das auch. Aber wir konzentrieren uns auf das Stream Processing, wo wir mit Echtzeitdaten arbeiten. Man kann sich vorstellen, dass man sich in die Plattform einloggt und direkt seine Events sieht, die gerade reinkommen. Beispielsweise drei neue Temperaturpunkte pro Sekunde, oder in einem Liniendiagramm, wie aktuell die Daten aussehen, damit ich wirklich damit arbeiten kann. Häufig starten die Entwickler nicht damit, direkt auf den Live-Daten zu arbeiten, sondern auf den statischen Daten Explorationen durchzuführen. Das ist der typische erste Schritt, wenn ich ein neues Modell entwickeln will. Häufig benutzt man dann ein Jupyter Notebook – was im Data-Science-Bereich ziemlich verbreitet ist. Das kann man sich vorstellen wie ein Arbeitsblatt, wo ich einfach Code auf Daten schreiben und damit experimentieren kann.
Wenn ich exploriert habe, beginne ich, Modelle zu schreiben und dann auch zu trainieren. Worum handelt es sich beim Trainieren? Sagen wir, wir möchten anhand verschiedener Input-Faktoren die geschätzte Bearbeitungsdauer als Zielvariable berechnen. Um dort die passende Gleichung aus Input und Output zu berechnen, speisen wir historische Daten ein, in denen wir Input und Output bereits kennen, und lassen für uns die Gleichung finden. Wenn mein Modell trainiert ist, dann nehme ich dieses Modell und setze es auf die Echtzeitdaten in meiner Plattform und schaue, wie sich das bei meinen Echtzeitdaten verhält.
Meistens passiert das zunächst in einer Testumgebung, damit man das nicht direkt live deployt. Sondern man lässt das ein paar Tage oder Wochen laufen und bekommt ein Gefühl dafür; aber auch kulturell muss viel passieren. Man muss in Unternehmen viel Vertrauen schaffen. Sobald dieses jedoch einmal besteht, dann deployt man es »in Production« und hat nun seine Stream-Processing-Applikation gebaut.
Vertrauen heißt in dem Sinne, dass man interne Überzeugungsarbeit leistet. Zu schauen, dass dieses Modell funktioniert und dass man Zugriff auf die Daten bekommt, richtig?
Clara
Das ganze kulturelle und auch Vertrauensthema ist ein großen Thema bei Machine Learning und Data Science. Da häufig ein gewisses Misstrauen dort ist, was wirklich passiert. Das liegt daran, dass schlechte Erfahrungen gemacht wurden, Fehler vorgefallen sind und sich das in der Folge eingeprägt hat. Dort geht es wirklich darum, Vertrauen in den Output dieses Machine-Learning-Modelles zu schaffen. Wenn das nun die Fabrikationsplanung übernimmt und automatisch berechnet, was als nächstes produziert werden soll, sodass eine Akzeptanz im Unternehmen geschaffen wird, dann ist man auf einem guten Weg. Wenn kleine Fehler passieren, muss ein Verständnis dafür geschaffen werden, dass die Maschine nicht der Allheilsbringer ist, sondern sich kontinuierlich weiterentwickelt, und dass das Ganze eine Reise ist.
Wie funktioniert es bei euch nun, die Daten weiterzuschicken?
Clara
Es ist ähnlich wie im Bereich des Ladens. Wir haben dort verschiedene Konnektoren, die wir bereits anbieten. Ich kann unter anderem auch wieder sehr einfach in mein Kafka reinsenden, in meine Streaming-Technologie. Ich kann es in eine Datenbank senden, aber auch wieder über Web Socket oder eine API sehr maßgeschneidert in mein System einsetzen.
Ihr stellt unterschiedliche Schnittstellen bereit. Sind das eure Partner, mit denen ihr dort zusammenarbeitet?
Clara
Richtig, denn wir ich bereits erwähnte, liegt bei uns ein großer Schwerpunkt darauf, ein breites Ökosystem zu haben und dort komplementär zu sein. Unser Ziel ist es, sehr gut mit diesen Partnern zu integrieren und bestmöglich an ein bestehendes Ökosystem einzubetten. Wenn wir als Beispiel Confluent nehmen, haben wir dort eine Partnerschaft und schauen, ob wir in bestimmten Use Cases gemeinsam arbeiten können, und helfen den Kunden in Zusammenarbeit, Stream Processing umzusetzen.
Das geht genauso mit einem Google- oder Amazon-Datenstream, nehme ich an, oder?
Clara
Auch das trifft zu. Das ist nicht nur Confluent, sondern beispielsweise auch die Kafka-Lösung von Amazon Web Services, da wir uns dort in alles einbetten wollen und dem Kunden an nichts binden wollen.
Das geht so weit, dass ihr sogar Slack Notifications oder E-Mails und Weiteres verschicken könnt. Jegliche Brands kann man mit anbinden.
Clara
Was über Slack hinaus ebenfalls beliebt ist, ist die Integration mit Twilio, ein Anbieter im Bereich Messaging und SMS. Wir haben dort nicht nur die Notifikation per Slack, was manchmal auf dem Shopfloor nicht praktisch ist, sondern auch eine SMS-Möglichkeit.
Ergebnisse, Geschäftsmodelle und Best Practices – So wird der Erfolg gemessen [35:18]
Hast du zum Business Case KPIs oder Erfahrungswerte, die du teilen willst, wieso dieses System einen Mehrwert bringt?
Clara
Wenn wir auf die Fabrikationsplanung zurückkommen, gibt es dort sehr viele positiv beeinflusste Metriken. Wir haben eine bessere Auslastung der Maschinen, eine geringere Lieferzeit, ein verbessertes Lagerbestandsmanagement. Und der größte Vorteil in der Fabrikationsplanung, das automatisiert durchführen zu lassen und dort einen Schwerpunkt zu setzen, ist, dass es sich um Prozesse sehr großer Komplexität handelt, die ein Mensch alleine nicht auffassen kann. Dafür ist unser Gehirn gar nicht gemacht. Allein wenn wir über End-to-End-Supply-Chain-Planung sprechen. Denn um End-to-End eine Bestellung zu produzieren, sind häufig hunderte Prozesse involviert, die teils verwoben sind. Es bestehen Abhängigkeiten und es läuft parallel. Häufig wird das in einem Unternehmen von unterschiedlichen Abteilungen übernommen, die dann ihre eigene Planung durchführen, aber man dadurch asynchron arbeitet.
Diese hohe Komplexität kann ein Algorithmus hingegen stemmen und bearbeiten, weshalb dort hohe Effizienzgewinne möglich sind. Im Fall unseres Kunden ist dort die Vision, irgendwann die Produktion zehnmal effizienter zu machen als eine herkömmliche Produktion. Ich will die Komplexität einer End-to-End-Supply-Chain-Planung untergraben. Natürlich ist das die Königsklasse, wenn wir über den gesamten Prozess sprechen, die aufeinander abstimmen zu lassen. Ein Kunde ist dort mit einem PoC gestartet, und das wird immer weiter ausgebaut.
Gibt es erste Erfahrungswerte, die du teilen möchtest? Hast du Fallstricke oder Best practices, von denen man lernen kann?
Clara
Ein sehr spannendes Learning ist, ob man das Ganze inhouse implementieren oder sich einer Agentur widmen sollte, die einen dort unterstützt. Wir haben bei diesem Fall die Erfahrung gemacht, dass es für den Kunden speziell sehr gut funktioniert hat, das Ganze inhouse abzubilden, da die Kapazität dort bestand und die Plattform mit viel Komplexität abstrahiert wird. Man muss sagen, dass bei dem Kunden das Thema Machine Learning und Daten eine hohe Unternehmenspriorität haben; das ist nicht in jedem Unternehmen so. Bei anderen gibt es wieder andere Ausrichtungen, wo wir empfehlen würden, mit Partnern zusammenzuarbeiten. Trotzdem sollte man das Ganze nicht als Outsourcing-Thema betrachten. Einfach nur eine Agentur bitten, das zu lösen, funktioniert nicht beziehungsweise sollte nicht das Ideal sein. Man sollte von der Kompetenz profitieren, da wir häufig Spillover-Effekte sehen. Wenn einen das Thema wirklich interessiert … andere Abteilungen kommen im Verlauf auch, wie die Finanzabteilung, die auch von der Datenplattform profitieren wollen.
Ihr wollt auch Interaktionen ermöglichen mit der Plattform. Man sieht, dass hunderte Use Cases von den Kunden bearbeitet werden, wo auch wieder verschiedene Abteilungen aufkommen, die unterschiedliche Daten wollen. Wenn man da keine skalierbare Architektur drunter hat, dann wird es schwierig. Euer Weg ist hierfür eine gute Möglichkeit.
Darfst du Zukunftspläne verraten?
Clara
Ich darf leider keine konkreten Planungen in unserer Produktplanung preisgeben, aber die Fokusthemen. Diese sind einerseits die Einbettung ins Ökosystem. Da gibt es sehr viel, wo wir uns immer besser integrieren wollen. Andererseits auch, immer mehr Werkzeuge den Entwicklern zur Hand zu geben. Da wollen wir unsere Möglichkeiten von verschiedenen Modellen im Bereich Monitoring erweitern. Dokumentationsmöglichkeiten wären auch noch ein weiterer Punkt, um eine Breite der Tools abzudecken, die benötigt werden, um end-to-end eine Stream-Processing-Applikation zu bauen. Wir wollen unseren Entwicklern die ganze Arbeit und Komplexität wegnehmen und sie übernehmen, damit sie sich auf das Wesentliche konzentrieren können.
Danke für deine Zeit und das interessante Gespräch. Ihr habt tolle Projekte. Vielen Dank, dass du heute mit dabei warst. Mach es gut!
Clara
Bis zum nächsten Mal!

