





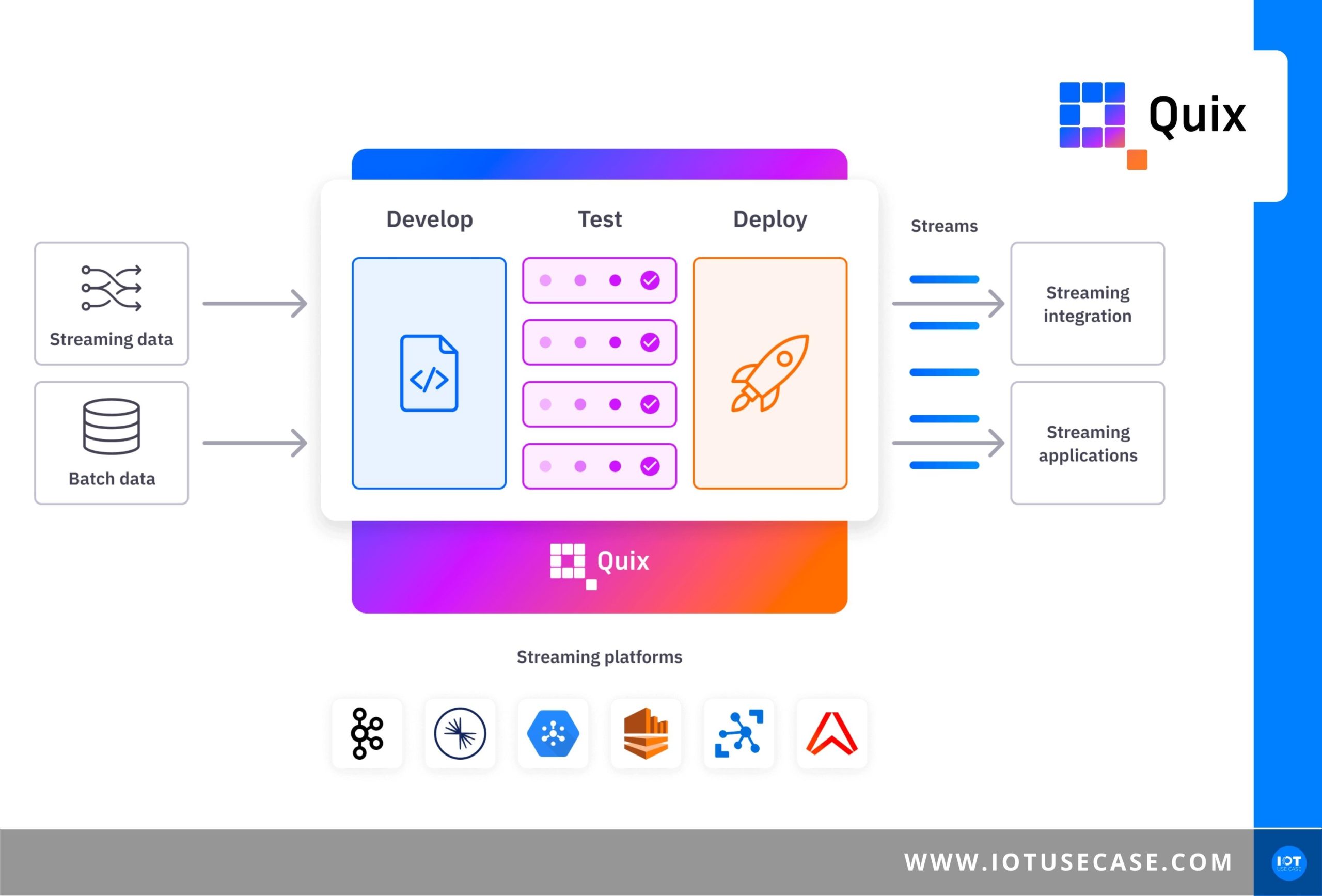
Event streaming usage is booming, but working with live data is often difficult. The goal of our podcast guest today, Quix, is to help data scientists and mechanical engineers use live data in their applications faster. On the PaaS (Platform-as-a-Service), the entire workflow can be managed – based on Python!
Episode 77 at a glance (and click):
- [10:55] Challenges, potentials and status quo – This is what the use case looks like in practice
- [23:48] Solutions, offerings and services – A look at the technologies used
- [35:18] Results, Business Models and Best Practices – How Success is Measured
Podcast episode summary
What is event streaming and how can companies benefit from it? How does it help developers like Data Engineers of IT Operations or Mechanical Engineers? What role does Kafka* play? And what does Kubernetes, the open source system developed by Google for managing container applications, have to do with it?
The guest on this episode of the IoT Use Case Podcast is Clara Hennecke (Streaming Advocate, Quix), who answers these very questions. Quix helps customers from a wide range of industries with a tool that enables developers to load real-time data from a wide range of infrastructure, transform data and, in the process, make data available in a wide range of systems, even without prior IoT knowledge. The Quix solution relies on Python and not only provides the technology itself, but lets entire workflows manage themselves.
We dive into three use cases in more detail in this episode:
1. eMan intelligent stethoscope from the field of medicine.
2. Mobility IoT in racing
3. Component business of a British company for CNC milling machines.
Podcast interview
Hi Clara, you are a so-called Streaming Advocate at Quix. You guys are in a specific market segment; but let’s focus on you first: What is a Streaming Advocate and what is your background?
Clara
Many might not know what my title means. Basically, my role is to talk a lot about streaming processing. This is on the one hand with our customers, potential customers, but also industry experts, to pass on the feedback internally to our team, and on the other hand to provide educational work. With stream processing – we have to be aware of this – we are talking about a technology that is very innovative. Often the question is not what specifically is the best technology. But first, what is it about and how can it help my business?
As I understand it, your core business with Quix is roughly software development – Platform as a Service. You bring with you a solution for IoT applications, where I can get access to a platform and work with my real-time data, with different building blocks that are already there. Both for connecting data, as well as transforming data and determining the destination, for example, where the data should go. Be it dashboards or other things. We also offer the possibility to combine a tool for Machine Learning.
There are many platforms on the market with different solutions. How exactly does your solution work and how is it different from others?
Clara
You summed it up quite well. What is streaming? There are many applications in a company. Actually, data is always generated in real time; be it a temperature being measured or an incoming order. And when we take that real-time data and push it out to different applications within our IT infrastructure, we call that data-sending-from-A-to-B “streaming.” To send this data, one uses various streaming technologies, such as Kafka.
If you don’t want to just send the data from one point to another, but transform it in real time, then you are dealing with stream processing. There are various technologies on the market. Confluent offers KSQL or Kafka streams for this purpose. Quix is also a stream processing solution. What makes us different is that our focus is on developing with Python, and on the other hand, we don’t just offer a technology, but an entire platform where a complete workflow can be managed.
If you want to learn more about real-time data, definitions and, what exactly Confluent does, you will find more in the show notes.
Confluent is your partner, you also implement such solutions that already exist at your company, but then work more on your solution with Python, right?
Clara
Exactly, our technology is complementary to Kafka. That is, many of our customers implement Kafka first, and build the pipes of real-time data in their business with it, and then put our platform on top of those pipes to have the development environment with Python and be able to develop with it.
In the end, Python is a programming language that is also used in IoT solutions that you rely on.
Clara
Right, if we look in the data space in general, there are two languages that dominate there. One is SQL and Python, with SQL being used more for analytical queries. More for questions like, “How many parts have I manufactured in the last three months?” A lot of work there is done on badge data, persistent data. Python is the language for data science and machine learning, i.e. more complex applications such as predictions or anomaly detection.
To create a benchmark: About 60 to 70 percent of all machine learning data science projects are done with Python. As a result, we have a large ecosystem based around the language.
It is exciting to dive into this database world. It is a platform that helps developers use or harness their applications faster with live data. The market of IT professionals is a challenge currently. That’s going to be primarily your target audience that you’re talking to, or of your customers, is that going to be the developers in the companies?
Clara
That’s all right. To come back to the point of our specific solutions for IoT, what solutions we specialize in and how we are aligned there: The platform in general is initially industry-independent. This is because there is a need for and also a benefit from stream processing in a wide variety of industries. This goes through e-commerce, the financial industry, the telecommunications industry or logistics industries, but of course IoT plays a very big role.
We have customers both in the IIoT area, but also in areas such as micromobility or logistics. Then, when we talk about the people in the companies that use our platform, in the broadest sense, we are talking about developers who develop with Python. I say that so broadly because it can be very different people depending on the company. Often these are people on a Data Team; Data Scientists or Data Engineers. But we also see, especially in the IIoT space, that it’s often mechanical engineers who have the use cases there, but also skills to build those applications with our platform.
Theoretically, there are many out there who have a different background or come from the automation world, from the programming world, and they can learn there to go towards IoT development with your platform.
Clara
Exactly, that is one goal of our platform. That we abstract away a lot of complexity and developers don’t have to be experts in IT infrastructure there. But rather experts in mapping a particular use case, translating it in code, and writing and implementing that code.
Why is what you are doing so important? What is your vision in the market? Maybe you can also tell something about the founding history.
Clara
Our four founders come from Formula 1, in racing, where a lot of data is collected. I didn’t realize it was such a big issue at the beginning, but a race car like this is equipped with a lot of sensors, which also sends a lot of data that is then passed on to the teams in the garages so that they can make the best decisions. Our founding fathers worked on these solutions involving these real-time data streams. That’s where it really comes down to real-time solutions.
We realized here that it’s all very complex and there was no way in the market at the time to just focus on the code and the things that create value. Developing a new model, testing a new model, deploying a new model are also part of it. All the interactions from the software engineers to other developers are very lengthy and you had to do a lot of loops there. It takes a very long time for a new model to actually go into production from the writing of the model. We would like to simplify and democratize the whole process.
You have to admit that streaming is technically very complex. What has to happen in the background of a Kafka so that not a single event is lost is very demanding. It is a very powerful technology. When we talk specifically about our robust platform base Kafka, we want to enable a wider range of people to work with this technology and build value-added applications.
Challenges, potentials and status quo - This is what the use case looks like in practice [10:55]
Because the topics are buzzword-heavy, I like to use real-world examples. What use cases are you currently working on and what are the solutions?
Clara
We have use cases in a wide variety of industries. Much comes from the financial and e-commerce industries. But since we focus on the IoT space, I brought three use cases that I’m going to talk about today. The first use case comes from the medical IoT sector. This is a start-up from England, eMan. The mission of eMan is to develop an intelligent stethoscope that evaluates recorded sounds in real time and draws information about condition of lungs, heart, intestines, blood flow. This involves taking audio files from this stethoscope, sending them via Bluetooth to a smartphone, which then sends the data to the Quix Cloud. There, the data is processed, visualizations are transformed, and then sent back to the smartphone, so I can get information about the condition right on my smartphone. This is an exciting use case, which can bring a very big progress in the medical field.
That’s the main area with us where we have a lot of product developers with us in the network that are looking at making their devices and components smart and creating an offering. They also rely on you.
What other use cases do you have?
Clara
In the second use case, we jump back into racing, into the mobility IoT space. During a race, huge amounts of data are collected by a wide variety of sensors. The customer here is a company that specializes in race car connectivity. This data has to be sent from the cars; however, the problem is that a car moves fast during a race and there are many influences that affect the network quality, such as the spectators or even the weather. There are different options during a race as to which network is currently the best. The customer then used the Quix platform to develop machine learning models that evaluate the quality of the network connection in real time and connect to the network that has the best connection at any given time. The whole thing can change up to 15 times per second. There we have been able to achieve a high gain in efficiency and a large increase in connectivity.
15 times per second is really a lot. For those who want to know more about the use cases and contact you afterwards, I link everything necessary in the show notes.
Which use case are we looking at in detail today?
Clara
The special third use case comes from the IIoT sector. Unfortunately, we cannot mention the name of the customer, but I try to give enough context to get the best possible picture. It is a British company that manufactures components for the aerospace, automotive, defense and energy sectors. For the most part, they use CNC machines and specialize in autonomous manufacturing. The goal in autonomous manufacturing is to create a network of the machines and robots, but also to form another planning and control software in the company. The important thing is to connect all of this in such a way that it communicates with each other and automatically adjusts to each other to enable highly agile and automated production in the end.
It’s not just about networking machines and plants, but also about integrating different systems that the customer already has there.
It is about a customer who has some CNC milling machines and robots of various lines. What do the processes look like here?
Clara
To make it easier, let’s go back to the use case: when you talk about Autonomous Manufacturing, there are a lot of processes that we can look at there. One of the first concrete processes that the customer has focused on in the data processing area is factory planning. When it comes to factory planning, there is planning software that already supports this – how exactly my processes run, when which part is produced on which lines. However, this was not enough for the customer; especially due to the fact that factories are very heterogeneous and individual. Every factory has different processes, different machines and different software in use. Factory planning optimally includes all components.
It is difficult to impossible to purchase standardized software that knows and optimally controls the interaction of my personal individual components. Therefore, the goal from the customer is to create a situation where at the end a CAD file comes in from his customer, it automatically calculates how the machine needs to be configured, calculates the estimated machining time, automatically adds the part to the schedule, and you improve delivery time and production utilization and increase efficiency throughout the production and supply chain.
There are challenges that your customers face, which is why they come to you. What are these challenges that you typically encounter in your day-to-day work?
Clara
There are two things. Many people think that the whole thing can be contradictory, but it’s what unites our platform in the end: on the one hand, a very resilient and sophisticated IT infrastructure. A stream processing system quickly takes six to twelve months and involves high costs. At the customer we talk about “high-frequency data” and move in the 100 kHz range. This means that certain applications collect 100,000 data points per second. As a benchmark, this quickly adds up to 5 GB of data per minute. These are very high demands on an IT infrastructure.
On the other hand, it is the desire to have control over the data themselves and to build up the expertise internally. Since our customer in particular saw this as a core competence, autonomous manufacturing and machine learning simply go hand in hand there. In addition, the advantage was seen in the fact that the in-house engineers know the machines and processes very well and can therefore accurately pass on and map their requirements to the models.
Combining the two was the challenge our client had and why we came together to work together.
With the race car, we have weather or localization data; with the medical issue, it might be audio data. In this specific case, it involves a wide variety of data, such as manufacturing planning data and CNC milling data. What is data that was important to your client and needed to be processed?
Clara
If you look at it in a higher-level way, the data can be divided into two types. Once it is the real-time data in the form of events. The other type is context data. Real-time data is time series data that has been given a specific time stamp. In the specific case of the customer, it was especially the data of the sensors and machines. For example, a particular operation is just starting or it is stopping, the exact position of the cutting head, or that a part has just left the machine. Once, what happens on my shop floor. But not only there are events and real-time data. But also in my surrounding planning of control software. A new order comes in or a shipment has been delivered. I see in my ERP that data has moved within my warehouse.
You have real-time data once. But without contextual data, the whole thing is often not very helpful. Imagine I have the event that part number ABC is being processed on the machine – but that does me little good without the context of knowing what exactly ABC is. An important context here would be how long the part number has taken on average on the machine in the past. This is not real-time data, but persistent data that is somewhere in my databases.
If I understand correctly, this is data that customers already have available in their local systems, which is retrieved there.
Clara
Right, that’s where connections to the local systems, to the databases are then created using connectors and interfaces and then fed into the system.
What are requirements from your customers who work with you on the solutions? You want to retain control over the data, yet you rely on an external partner, which is then integrated into my business model as a Platform as a Service.
Clara
First of all, the most important thing is that our platform is flexible. The customer is never a blank slate. There are already systems that were probably implemented at a time when stream processing was not thought of. There is an existing ecosystem, and there it is important that we can insert ourselves very flexibly with a wide variety of data sources. Also very important is that companies increasingly want to be cloud-independent. That means they don’t want to be locked into a specific provider and only work with Amazon Web Services forever, for example; but always have the option to change that. We also see this as an important requirement that is becoming more and more prevalent.
When I imagine your manufacturing company working with different suppliers and customers … each relies on a different platform. It may be that new requirements come in in this direction and that you have to be more flexible, right?
Clara
Absolutely! And really owning the interfaces to the systems there. That’s one of the priorities we’re focused on, creating a broad ecosystem there.
Are there any other requirements?
Clara
This is the basic requirement of customers to us. In addition, there are things like data security, the ease of use of the platform, resilience, the scalability of the platform or also the costs, because you don’t want to commit to one platform in the next five years – it will then grow and generate much more data – but then have to reckon with very high costs. Unfortunately, we see this more and more with other software, where customers start with relatively small data, such as an initial PoC, then expand the whole thing – which is very nice and also the goal – but are then faced with high costs. However, this is not the case with us.
Solutions, offerings and services - A look at the technologies used [23:48]
I myself was already allowed to look in on you and got access to how it works for you. You get a login to your platform, where there are different areas, which are already ready as building blocks. Be it connectors for various data sources, which can come from time series data, among other things, but also a wide variety of inventory data that can be connected there. Then follows already the transformation of the data and finally where the data should end up.
I think it’s very well implemented, also what you just mentioned with the UX (user experience) with the usability. But how exactly does the platform work? I would like to know more about data collection, its processing and further steps.
Clara
Data acquisition begins when the data is loaded into the platform. We have various integrations with existing solutions, so that you simply have to enter a token, for example, and you are automatically connected to an existing database that you have somewhere; the data is automatically streamed in there. We also have other interfaces such as a “web socket interface” where another system would write the data into our platform. We also provide a classic REST API, which again would be an interface for how we get the data into our system.
Part of our solutions is called “Quix Client Library”, which is in effect a code, an SDK (Software Development Kit), which the customer can implement in their software, and there with the code snippet stream the data into our platform.
A wide variety of developers are working on the solution. You have already built a large ecosystem of different available interfaces.
Clara
Beyond that, we’re working very actively to build a community and we’re seeing that grow a lot, and then they’re writing new connectors themselves, so that evolves through the community and the ecosystem continues to grow there.
Keyword open source, so that one has the possibility to bring in own solutions at that point. Do you have some examples of the data records, what are the connectors? Assuming I have time series data from the CNC milling machine – is there a connector for it there or does your customer develop it themselves?
Clara
It depends on what exactly is being used on the shop floor to stream these sensors. For example, in the current use case, we were sending data from the sensors to a Linux box positioned on the shop floor, and the data was arriving in OPC UA format – which is a common data format used to connect machines. This Linux box then has our Quix Client Library installed, which takes this data from the format and then transforms it into the format that is optimized for streaming and time series data, then connects to the Internet and sends it to the cloud.
This is a newer standard. But if I have an old machine, I would also have the possibility to connect it with another interface, right?
Clara
That would also be possible. Our platform is very flexible in this respect. We have not yet covered every use case out of the box. However, in these cases we often work with the customer to provide a solutions engineer. He makes this application for the customer and performs the initial effort. It’s usually two to three days of writing this code, which then turns the data into a format that can be streamed into the Quix platform.
How exactly does the processing of data within your platform work?
Clara
There are these three areas that data is loaded into the platform, transformed there, and then sent on out of the platform. We are now talking about the second step, transforming the data, which is definitely where the focus of our platform is and, in my opinion, where the focus of any data application should be. I don’t want to spend a lot of time just loading data somewhere, but rather on completing the transformation and creating the value. This happens on our platform and can basically be divided into two processes. Once in Stream Processing, but also Badge Processing.
Regarding badge processing: these are data transformations that do not run permanently, but at a certain point in time, where I do not have a real-time requirement. For this purpose, data is stored in databases; this can happen directly in our platform. One can set with a mouse click that one wants to persist one’s data and store it in a database managed by us, for example to use the data to train models. On the other hand, we also have connectors to databases like Snowflake, Redshift, or Microsoft SQL Server, where the data is sent, where I can run my badge processes.
That is not our focus. We see that use cases exist there and we enable that. But we focus on stream processing, where we work with real-time data. You can imagine logging into the platform and directly seeing your events coming in. For example, three new temperature points per second, or in a line graph, what the data currently looks like so I can really work with it. Often, developers don’t start by working directly on live data, but instead perform explorations on static data. This is the typical first step when I want to develop a new model. Often people then use a Jupyter notebook – which is quite common in the data science field. You can think of it like a spreadsheet where I can just write code on data and experiment with it.
Once I’ve explored, I start writing models and then training them as well. What is training about? Let’s say we want to calculate the estimated processing time as a target variable using various input factors. To calculate the appropriate equation there from input and output, we feed in historical data in which we already know input and output, and let it find the equation for us. Once my model is trained, then I take that model and put it on the real-time data in my platform and see how that behaves on my real-time data.
Most of the time, this happens in a test environment first, so you don’t deploy it live right away. But you let it run for a few days or weeks and get a feel for it; but also culturally a lot has to happen. You have to create a lot of trust in companies. However, once this exists, then you deploy it “in production” and now you have built your stream processing application.
Trust, in that sense, means internal persuasion. To see that this model works and that you can get access to the data, right?
Clara
The whole cultural and also trust issue is a big issue with Machine Learning and Data Science. Since there is often a certain distrust there, what really happens. This is because bad experiences have been made, mistakes have occurred and this has subsequently become ingrained. That’s where it’s really about building confidence in the output of that machine learning model. If this is now taken over by factory planning and automatically calculates what is to be produced next, so that acceptance is created in the company, then you are on the right track. When small mistakes happen, there needs to be an understanding that the machine is not the panacea, but is continually evolving, and that the whole thing is a journey.
How does it work for you now to send the data on?
Clara
It is similar to the store area. We have several connectors there that we already offer. Among other things, I can also send back into my Kafka very easily, into my streaming technology. I can send it to a database, but I can also put it back into my system via web socket or an API in a very customized way.
You provide different interfaces. Are those your partners that you work with there?
Clara
Right, because as I mentioned, we have a big focus on having a broad ecosystem and being complementary there. Our goal is to integrate very well with these partners and embed in the best possible way to an existing ecosystem. If we take Confluent as an example, we have a partnership there and see if we can work together in certain use cases and help customers in collaboration to implement stream processing.
It works the same way with a Google or Amazon data stream, I assume, right?
Clara
This is also true. That’s not just Confluent, but also Amazon Web Services’ Kafka solution, for example, because we want to embed ourselves in everything there and not tie the customer to anything.
This goes so far that you can even send Slack notifications or emails and more. Any brands can be included.
Clara
What’s also popular beyond Slack is the integration with Twilio, a messaging and SMS provider. Not only do we have Slack notification there, which sometimes isn’t practical on the shop floor, but we also have an SMS option.
Results, Business Models and Best Practices - How Success is Measured [35:18]
On the business case, do you have any KPIs or experiential data you want to share on why this system adds value?
Clara
If we go back to factory planning, there are a lot of positively impacted metrics there. We have better utilization of machines, reduced delivery time, improved inventory management. And the biggest advantage in factory planning, to have that automated and to put a focus there, is that these are processes of very great complexity that a human alone cannot grasp. Our brain is not made for that. Just when we talk about end-to-end supply chain planning. Because to produce an order end-to-end, hundreds of processes are often involved, some of which are interwoven. There are dependencies and it runs in parallel. Often this is done by different departments in a company, which then do their own planning, but they work asynchronously as a result.
An algorithm, on the other hand, can handle and process this high complexity, which is why high efficiency gains are possible there. In the case of our customer, the vision there is to eventually make production ten times more efficient than conventional production. I want to undermine the complexity of end-to-end supply chain planning. Of course, when we talk about the whole process, getting those aligned is the supreme discipline. One customer started there with a PoC, and that is being expanded.
Are there any initial lessons learned you’d like to share? Do you have any pitfalls or best practices to learn from?
Clara
One very exciting learning is whether you should implement the whole thing in-house or turn to an agency to help you there. Our experience in this case was that it worked very well for the customer specifically to map the whole thing in-house, because the capacity existed there and the platform is abstracted with a lot of complexity. It has to be said that at the customer, the issues of machine learning and data are a high corporate priority; that’s not the case at every company. For others, there are other orientations where we would recommend working with partners. Nevertheless, the whole thing should not be seen as an outsourcing issue. Simply asking an agency to solve it doesn’t work, or shouldn’t be the ideal. One should benefit from expertise, as we often see spillover effects. If you’re really interested in the issue … other departments come along in the course, too, like the finance department, who also want to benefit from the data platform.
You also want to enable interactions with the platform. You can see that there are hundreds of use cases being worked on by customers, where again different departments come up that want different data. If you don’t have a scalable architecture underneath, then it becomes difficult. Your way is a good way for this.
Can you reveal future plans?
Clara
Unfortunately, I am not allowed to disclose any specific plans in our product planning, but the focus topics. On the one hand, these are the embedding in the ecosystem. There is a lot where we want to integrate better and better. On the other hand, also to give more and more tools to the developers. That’s where we want to expand our options from various models in the area of monitoring. Documentation capabilities would also be another point to cover a breadth of tools needed to build end-to-end a stream processing application. We want to take all the work and complexity away from our developers and let them focus on what’s important.
Thank you for your time and the interesting conversation. You have great projects. Thank you so much for joining us today. Take care!
Clara
Until next time!

